This time, the experiment is repeated on the same node (btc2 on the DKRZ testystem) and using the exact same kernel but in one case we had KPTI enabled and in the other it was disabled using the debug interface: /sys/kernel/debug/x86/pti_enabled.
Also the overall benchmark suite was not only run 50 times but more than 500 times in each configuration.
Again, 10 processes have been used.
Results
An overview is given in the following table:
| Experiment | Relative speed with KPTI |
| ior_easy_write | 0.995 |
| mdtest_easy_write | 1.011 |
| ior_hard_write | 0.991 |
| mdtest_hard_write | 1 |
| find | 0.973 |
| ior_easy_read | 1.002 |
| mdtest_easy_stat | 1.003 |
| ior_hard_read | 1.015 |
| mdtest_hard_stat | 0.999 |
| mdtest_easy_delete | 1.001 |
| mdtest_hard_read | 0.969 |
| mdtest_hard_delete | 0.993 |
So that means that overall a few experiments now run by 3% slower (find, mdtest_hard_read), but easy write is 1% faster.
The following graphs provide boxplots of the indiviual repeated measurements with enabled/disabled KPTI:
 |
| Fig1: IOR measurements |
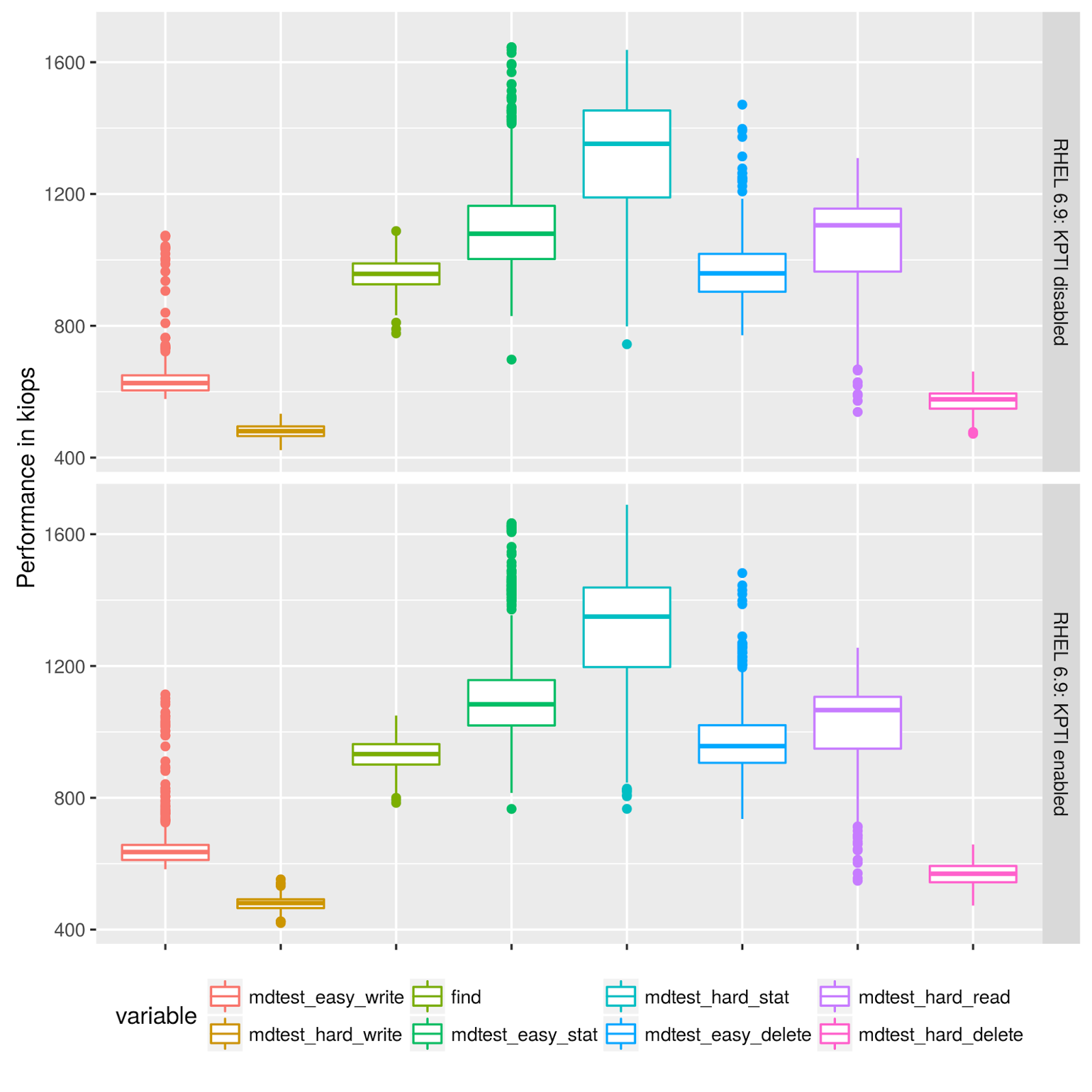 |
| Fig2: Metadata measurements |
While there are some outliers in both configurations, the overal picture looks comparable.
Conclusions
The impact of KPTI is neglectable on our sytem for I/O benchmarks as particularly Lustre is significantly slower than using tmpfs, the results for IO-500 are similar with the results when analyzing latency more fine grained as in my previous post about the latency of individual operations.




Keine Kommentare:
Kommentar veröffentlichen