The patches for the bug Meltdown and Spectre may be performance critical for certain workloads. This is particularly crucial for data centers and HPC workloads. Researchers started to
investigate the impact on HPC workloads, so for example, looked at the performance of IOR and MDTest showing that MDTest is severely impacted. This suggests that applying the patch may impact performance intercomparison efforts such as by the
IO-500 list which aims to track storage performance across file system and time. To do so, a measurement procedure and scripts are provided.
At the German Climate Computing Center (
DKRZ), a RedHat Enterprise 6 Linux is used and also affected by the Meltdown and Spectre CPU bugs. A relevant question was how much will these bugs affect the IO-500 measurements. However, measurement of the impact is not easy in this setup as all nodes of the test system have been updated with the new kernel and this update comes along with an update of the Lustre client code that resolves several issues on the DKRZ system.
Note that a new post with statistically better analysis is available here.
A first measurement of the impact
A first and simple approach that fits into the current situation has been conducted as follows:
- Setup the IO-500 benchmark on the test system and the production system with the old kernel
- Run the IO-500 benchmark on tmpfs (/dev/shm) to exclude the impact of the Lustre system
- Repeat the measurement 50 times and perform some statistical analysis
Test setup
Both nodes are equipped with the same hardware particularly two Intel Xeon E5-E2680v3 @ 2.5 GHz microprocessors. The unpatched node uses the kernel 2.6.32-696.16.1.el6 and the node with the bugfix the kernel 2.6.32-696.18.7.
For the IO-500 configuration, the following parameters where used:
io500_ior_easy_params="-t 2048k -b 2g -F" # 2M writes, 2 GB per proc, file per proc
io500_mdtest_easy_params="-u -L" # unique dir per thread, files only at leaves
io500_mdtest_easy_files_per_proc=50000
io500_ior_hard_writes_per_proc=10000
io500_mdtest_hard_files_per_proc=20000
12 processes are started using srun, i.e., 12 times the number of files or data volume is actually used. Each individual benchmark run takes about one second to run; since the throughput and metadata rate is very high, the main memory is quickly full not allowing to run the benchmarks for larger settings.
Results
Boxplots for IOR are shown in the following diagram, i.e., the first and third quartile of the 50 measurements comprise the box and the median is the vertical lines, whiskers and outliers are shown:
There are quite some outliers due to the short runtime and the short wear-out phase of IOR, but in general the picture looks similar:
There is no significant observable performance degradation to this benchmark.
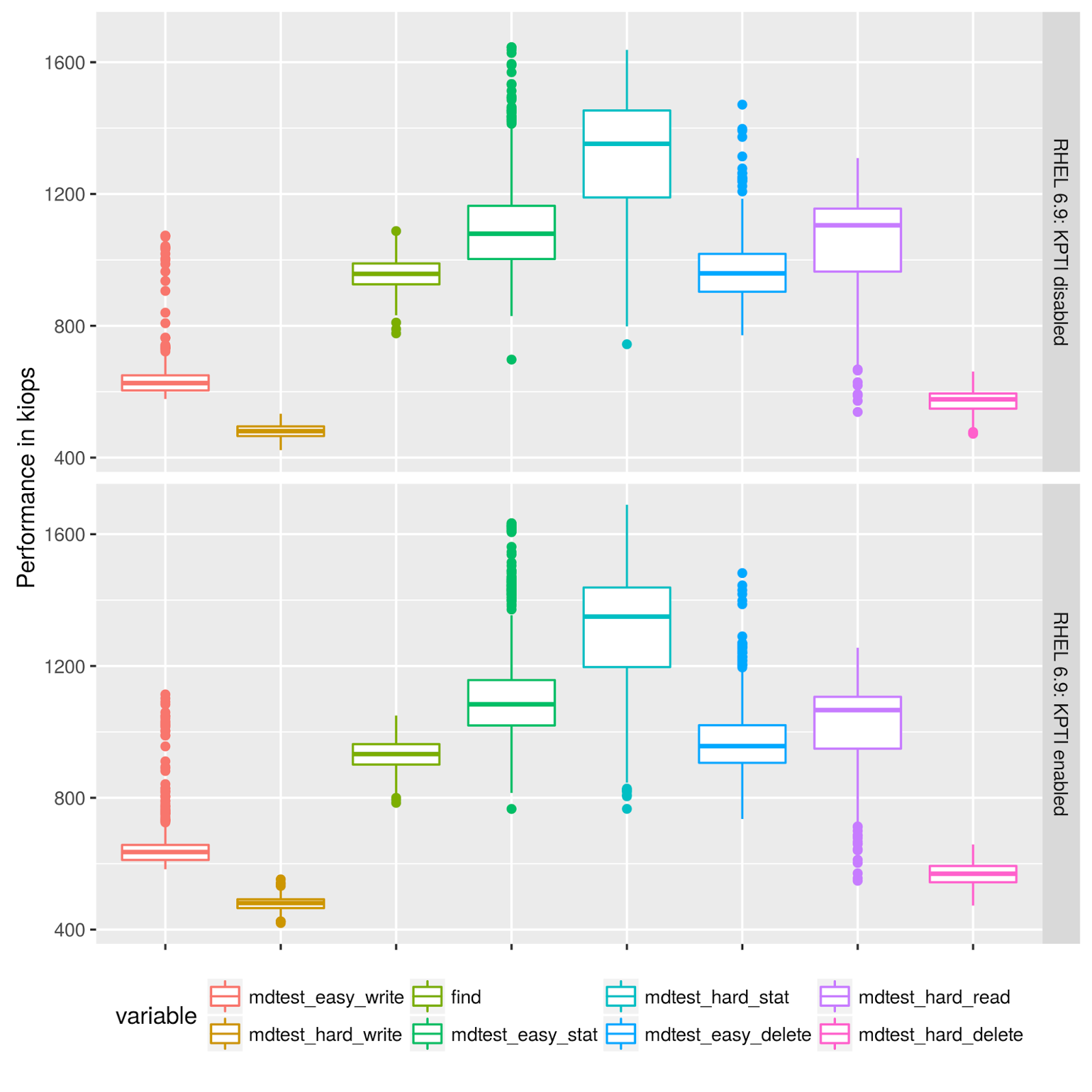
Results for MDTest in this diagram behave generally similar, too:
Now, we compute the mean(patched)/mean(unpatched) for each performance number in the order as reported by the IO-500:
ior_easy_write = 1.062
Thus, the measurement in the patched version is 6% slower.
mdtest_easy_write = 0.962
Thus, the patched kernel is 3.8% faster than the old version.
The other values are similar with the exception of find and the ior_easy_read there actually is a 13% overhead in the new versions.
ior_hard_write = 0.973
mdtest_hard_write = 0.976
find = 1.132 # So this is considered to be 13% slower
ior_easy_read = 1.142 # This is 14 % slower
mdtest_easy_stat = 0.991
ior_hard_read = 1.001
mdtest_hard_stat = 0.981
mdtest_easy_delete = 0.961
mdtest_hard_read = 0.943
mdtest_hard_delete = 0.982
The values suggest that the patched version is actually often a bit faster, and a t-test confirms that in some cases, but take these numbers with a grain of salt as this quick measurement is biased:
- Measurement is not conducted on the exact same hardware, there might be minimal differences albeit the same hardware components are used.
- There are many outliers, therefore, the 50 repetitions are not sufficient.
However, it does show that the kernel update is not too worrisome; the values measured are similarly and not up to 40% slower as indicated by the paper cited above. Since Lustre is significantly slower than tmpfs, the impact on it is anticipated to be low. Certainly, the measurement should be refined and conducted on the same node to remove that bias and it should be repeated more often.